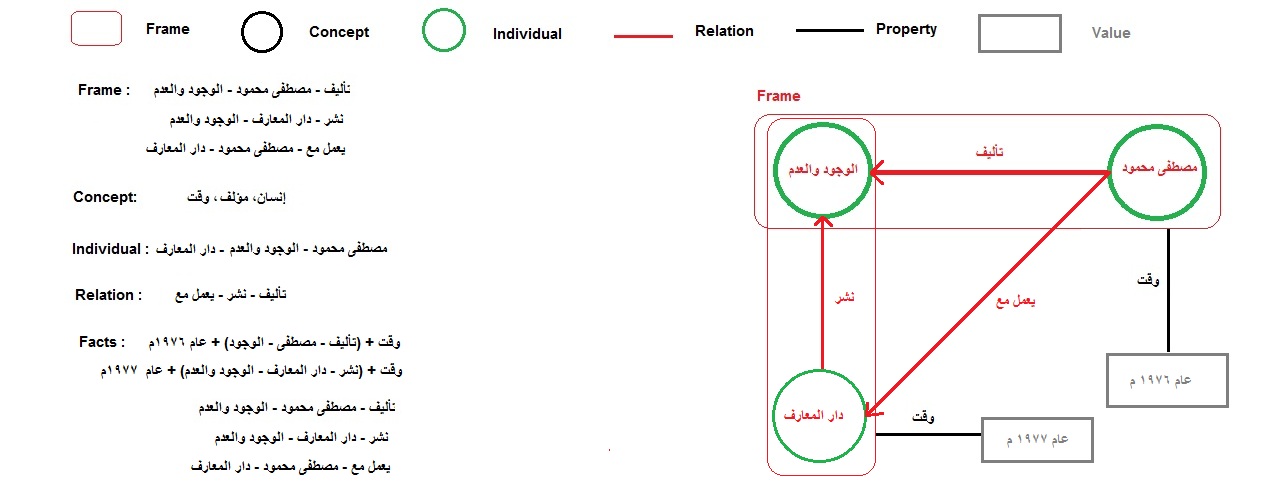
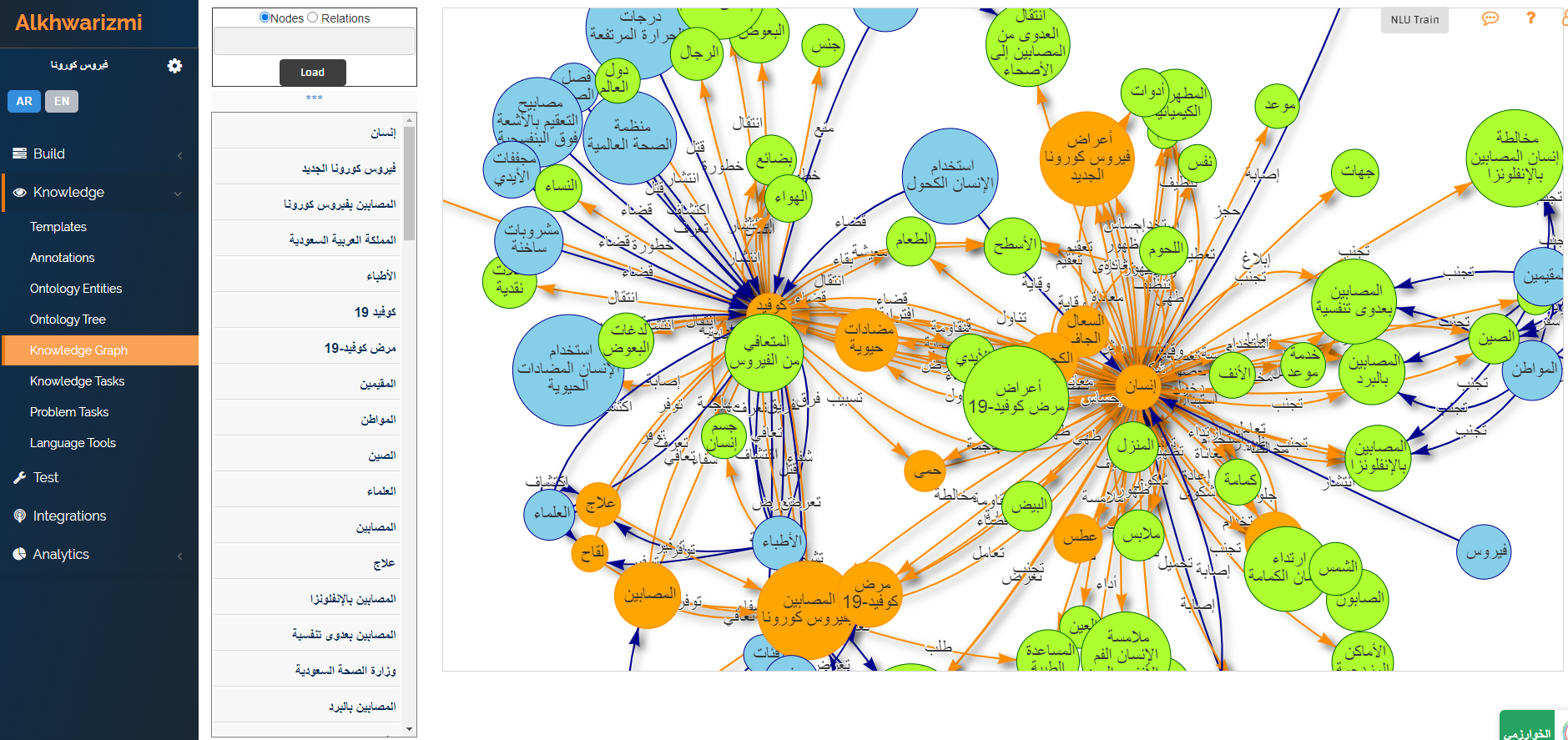
Major NLP Engine in Alkhwarizmi
Morphological analyzer & generator, Spell checker, Parser.
Morphological analyzer & generator:
The Morphological analyzer&generator is a vital component of almost every NLP processor.
Analyzer reduces the words into their common form.
Generator works in the opposite direction, generating words in their final inflected form as
they appear in the running texts.
The analyzer&Generator Engine.
Based on this equation :
WordToken = Prefix + ( stem || Irregular stem ) + Suffix
Alkhwarizmi developed its analyzer&generator engine ,in accordance with the idea of stripping
and concatination ,so that :
Stemmer = word token stripping
Generator = affix - concatenation
To reduce a word token back to its stem ,the stemmer strips it of all prefixes and suffixes in
order to bring it back to its original uninflected form .The reverse operation is performed by
the generator ,which concatenates the erased affixes back to the stripped stem so that an
ultimate word is produced with full morphological representation .
Spell checker:
Employing the results of our Morphological analyzer, Our Speller is designed to offer the user
the appropriate choices for the corrected spelling of a misspelled word in the order of their
likelihood.
Parser :
The parser is the most critical part of a Natural Language Processing system.
It decomposes the input sentence into its syntactical constituents.
It resolves different types of ambiguity, namely those ambiguities related to syntax, parts of
speech, and word sense.
A parser is typically composed of three fundamental parts.
The Parsing Engine.
A distinguishing feature of our parsing engine ,which makes it distinct from other parsing
engines available ,is its reliance on a unique control strategy and an innovative preferential
scheme.
The Control strategy combines MultiStack parser & deterministic parser, which reduces the
over-generation resulting from the MultiStack parser and prevents the structural determinism
caused by the deterministic parser.
The preferential scheme is applied to further restrict the number of parsing results. This
preferential scheme can be applied either during structure formation or after the parsing has
been completed.
The Formal Grammar .
A distinguishing feature of our parsing engine ,which makes it distinct from other parsing
engines available ,is its reliance on a unique control strategy and an innovative preferential
scheme.
The Lexical DataBase.
To embed multi-linguality at the lexical level, generic data structures universal to all
languages have been used. Our lexical database does not handle lexical entries as separate
stand-alone items, but as an intricate, entangled forest of interrelations. It draws relations
between verbs and their derivatives, synonym relations, etc.